tensorflowの転移学習のチュートリアルを解説(modelの保存、自前の画像分類まで)
google colaboratoryでチュートリアル開始
さてchat GPTが凄すぎて、もうコードを書く必要がなくなるのでは??と思うほどの インパクトでしたが、どうやらまだ人間が手助けをする余地はありそうです。 AIに衝撃を受けた僕は、ふとtensorflowの勉強をしてみることにしたのです。 tensorflowは言わずと知れたgoogleのdeep learning向けのライブラリです。 機械学習にはGPU等を使用します。僕のパソコンでは以前にdezeroを使ってチャットボット を作った環境があるのでGPUはあるのですが、tensorflowをダウンロードしたりと 環境構築がなんとなくめんどい印象でした。 そんな僕を助けてくれたのが、google claboratoryです。今後はcolabと書きます。 これはgoogleのアカウントがあれば誰でも使用できます。とっても便利!! 簡単に言えばpythonもtensorflowも入ってて、その他もpip installしないでnumpyとかが、 簡単に使える環境です。僕はgoogle driveから使用しています。 使い方は簡単で、グーグルドライブ上で右クリックして、その他からgoogle colaboratoryを 選ぶだけです。 今回はこのcolabでtennsor flownのチュートリアルの内の転移学習をやったので、 自分の勉強のためにブログに書くことにしました。 転移学習の後で、自分で追加として、modelのセーブ、そしてセーブしたmodelを自分のパソコンに ダウンロードする方法、そして今後はパソコンからcolabにアップロードして、そのモデルを 使用して、自分で用意したjpgの画像をmodelを使用して分類するまでを解説しています。 ここまでやれば、結構機械学習した気がすると思います。是非最後まで読んでください!! 注!!間違っていることもあると思いますが、ご容赦ください。機械学習ってなんだろうって 方が機械学習に触れる最初の機会、程度を想定しているので。温かい気持ちで読んでくださいませ。
tensorflowインポートから画像の前処理
まずは必要なライブラリをimportしていきましょう。pythonでお馴染みのimportを以下コードで行います。
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
上記が出来たら次は実際に機械学習していく、画像をダウンロードします。 画像は犬と猫の画像がたくさんあります。目的のタスクは画像の犬猫分類機の作成です。
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cat_and_dogs.zip', origin=_URL, extract=True, cache_dir="./")
上の2行目のコードで指定のURLから画像をダウンロードしています。 get_file(cache_dir="./")でカレントディレクトリに保存先を変更できます。 デフォルトのままですと、簡単にファイル構造がみれない場所に保存されるので、今回は見やすい 場所に保存します。
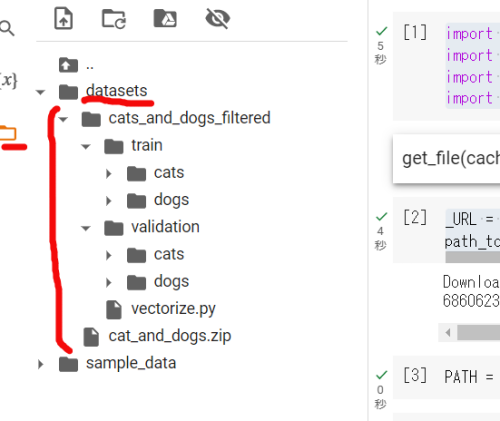
ファイルは上記の様な構造になっています。左の箱のようなボタンを押すとファイルがみれます。 トレーニング用と検証用(validation)の中にそれぞれcatsとdogsのフォルダーがあります。 このフォルダー名が画像のclass_nameになります。
続いてこれらの画像を実際にトレーニング様と検証用の画像に分けていきましょう。
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
ファイルの内容がわかるとコードの中身も分かりやすいですよね。 train_dirにtrainファルダのパスを、同様にvalidation_dirにvalidationのパスを設定しています。
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
train_dataset = tf.keras.utils.image_dataset_from_directory(
train_dir,shuffle=True,batch_size=BATCH_SIZE,image_size=IMG_SIZE
)
validation_dataset = tf.keras.utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
BATCH_SIZEはニューラルネットワークの訓練中に一度に処理するデータサンプルの数を指します。 IMG_SIZEに画像をリサイズしています。image_dataset_from_directoryではフォルダーを指定し、 その中のフォルダー名をclass_nameとして、class_name毎に分かれた画像をオブジェクトして返してくれます。 とても便利な関数ですね。 これでトレーニングと検証用のデータセットが作れます。
class_names = train_dataset.class_names
print(class_names)
上記コードで['cats', 'dogs']って返されます。学習の結果分類の結果は数字ででてくるので、 0:cats 1:dogsという事がわかります。それではどんな画像があるのか実際にみてみましょう。
plt.figure(figsize=(5,5))
#tain_datasetを使うにはまずバッチを取得,take(1)で1バッチ分取得
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3,3,i+1)
#imageは0-1に正規化されているのでこれを0-255に戻す、uint8が0-255の範囲
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
plt.show()

コードと出力結果です。この画像達を使って機械学習していきます。そして次にテスト用の画像を 準備します。検証用あるじゃんと思うかもしれませんが、トレーニング中に、epoch毎に学習結果を 確認するためです。つまりトレーニング中にトレーニング画像での正答率と検証用(トレーニングに 使用していない画像)での正答率を表示するためです。これを確認することでトレーニング中に過学習 などが起きてないか確認できます。そしてそれで十分な結果がでたら、model.evalusateでトレーニングに 使用してない検証でも使用していないテスト用を使用して正答率を評価するということです。
#バッチ数を取得 320枚の画像があり1バッチが32枚なら10をかえす
val_batches = tf.data.experimental.cardinality(validation_dataset)
#val_bachは上の例なら10があるのでtakeするのは2個つまり20%がtest用
test_dataset = validation_dataset.take(val_batches // 5)
#さっきの2個をスキップしているので80%が残るのvalidationは80%になる
validation_dataset = validation_dataset.skip(val_batches // 5)
上記コメントの通りです。これでテスト用のtest_datasetも出来ました。 続いてデータセットのパフォーマンスを上昇させるために以下のコードを実行。 うーんこれは詳しくはわかりません。GPT君に聞いた解説を載せておきますね。
AUTOTUNE =tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
このコードは、データセットのパフォーマンスを向上させるために、prefetchを使っています。 prefetchは、トレーニング中にGPUがバッチを処理している間、次のバッチを同時に読み込むことで、 データの読み込みと処理をオーバーラップさせることができます。 これにより、データの読み込みがボトルネックになることを防ぎ、トレーニングの効率を向上させる ことができます。 buffer_size=AUTOTUNE は、TensorFlowにバッファサイズを自動的に調整させるように指示しています。 これにより、実行時に最適なバッファサイズが選択され、データの読み込み速度が最適化されます。 train_dataset、validation_dataset、およびtest_dataset のすべてに prefetch を 適用することで、それぞれのデータセットでデータの読み込み速度が最適化されます。
まぁ要するに学習の高速化に必要な処理ってことですね。
画像データの拡張
さてtrain,test,validationのそれぞれのデータセットが出来ました。しかし 画像の量がややこころもとない場合もあるでしょう。ここで画像データの水増し 作業を行います。
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2)
])
上のコードでは水平方向に画像をひっくり返したり、ローテーションしたりして画像を ふやしています。百聞は一見にしかずですので見てみましょう。
from tensorflow._api.v2 import data
for image, _ in train_dataset.take(1):
plt.figure(figsize= (8,8))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3,3,i+1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0].numpy().astype("uint8"))
#plt.imshow(augmented_image[0] / 255) こっちはエラーになる
plt.axis('off')

なんでかチュートリアルのままのコードだとエラーでたので一部変更しています。 画像みればどうやって画像データをふやしているかわかりますね。このような微妙な 違いのある画像があるおかけで過学習になりにくくなりますね。
MobileNetV2を使って画像分類してみましょう
#MobileNetV2のデータを使用しやすい形に変更するためのpreprocess_inputを準備
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
一般的な画像の正規化では大体は/255をして、0-1にするんですが、 MobileNetV2では-1から1にするんですが、 この処理をしてくれるpreprocess_inputを準備しておきます。
#IMG_SIZEは(160,160)で以前に指定、これに(3,)を+して(160,160,3)にしている
#3はrgbに対応、これで入力できる形に変更
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(
input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet'
)
さて上記でbase_modelにMobileNetV2のmodelを準備します。 学習済みの重みとしてimagenetを指定していますね。 引数 include_top=False を指定して、上位の分類レイヤーを含まない、 特徴抽出に理想的なネットワークを読み込みます。 この特徴量を抽出することのできるbase_modelの出力をみてみましょう。
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)
このコードの1行目は僕には難しかったですがやっている事は以下のコードと 大体同じです。いっこずつ取り出すイメージですね。
for image_batch, label_batch in train_dataset:
break
さて出力をみてみましょう。(32, 5, 5, 1280)と出力されます。
それぞれの数字の説明をしましょう。
32:バッチサイズ。この場合、一度に32枚の画像がモデルに入力されます。
5:特徴マップの高さ。MobileNetV2が画像を畳み込み処理した結果、
得られた特徴マップの縦サイズが5です。
5:特徴マップの幅。MobileNetV2が画像を畳み込み処理した結果、
得られた特徴マップの横サイズが5です。
1280:特徴マップのチャネル数。
MobileNetV2の特徴抽出部分が1280個のチャネルを持っているため、
特徴マップの深さが1280になります。
#mobilenetv2のモデルのレイヤーの重みを更新されないようにしておく
base_model.trainable = False
この後で学習する過程で、せっかくの重みが更新されてしまっては困るので、 重みが更新されないように上記コードで重みの更新を凍結しておきます。 ここまでで、一度 base_model.summary() を入力してモデルの内容を 確認してみてください。出力結果はかなり長いのでここでは掲載は省きます。 Total params: 2,257,984 Trainable params: 0 Non-trainable params: 2,257,984 最後にはこのようにパラメーターが 表示されるはずです。パラメーターは全て凍結されていますね。
#(バッチサイズ, 高さ, 幅, チャンネル数)から(バッチサイズ, チャンネル数)に変更している
#平均を利用してパラメータの削減と空間次元の削減をしている
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
上記の出力はこのようになります。(32, 1280)そして、これから猫か犬かの 予想を出力するmodelに変更します。出力は0から1の間が出力され、0に 近ければ猫、1に近ければ犬です。これには出力ユニット1の全結合レイヤーを 追加します。
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
このコードの出力は(32, 1)です。
ここまでやってきた事をまとめて新しいmodelを作ります。
inputs = tf.keras.Input(shape=(160,160,3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
inputs = tf.keras.Input(shape=(160,160,3)): モデルの入力層を定義します。 画像の形状は(160, 160, 3)で、3つの色チャンネルを持つ160x160ピクセルの画像を 入力として受け取ります。 x = data_augmentation(inputs): 入力画像にデータ拡張を適用します。この操作は、 画像の水平フリップや回転などの変換を行い、データセットの多様性を増やします。 x = preprocess_input(x): MobileNetV2モデルに適した形式に入力画像を前処理します。 x = base_model(x, training=False): 前処理された画像を、学習済みのMobileNetV2 ベースモデルに入力します。training=Falseは、ベースモデルのバッチ正規化レイヤーが 推論モードで動作することを示します。 x = global_average_layer(x): MobileNetV2からの出力特徴マップに、 全域平均プーリング(Global Average Pooling)を適用します。 これにより、特徴マップが1次元の特徴ベクトルに変換されます。 x = tf.keras.layers.Dropout(0.2)(x): ドロップアウトレイヤーを適用して、 過学習を防ぐために特徴ベクトルの一部をランダムに無効にします。 この例では、ドロップアウト率は0.2(20%)です。 outputs = prediction_layer(x): 特徴ベクトルに全結合(Dense)レイヤーを適用し、 2つのクラス(犬または猫)の分類問題に対するスコアを生成します。 model = tf.keras.Model(inputs, outputs): 入力と出力を指定して、 Kerasモデルを構築します。これで、画像分類モデルが完成し、学習や推論に使用できます。
さていよいよ、modelをcompileしましょう。
base_learning_rate = 0.0001
model.compile(
optimizer = tf.keras.optimizers.Adam(learning_rate=base_learning_rate),
loss = tf.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy']
)
まずは学習率を指定。これはチュートリアルのまんまの数字にしています。 そしてよく出てくるけど意味不明なfrom_logits=Trueの説明を以下に from_logits=Trueは、損失関数のパラメータで、モデルが出力する予測値がロジット (未加工の予測値)であることを示しています。ロジットは、通常、 活性化関数が適用される前のモデルの出力を指します。この場合、 活性化関数はシグモイド関数です。 from_logits=Trueを指定すると、損失関数(この場合はBinaryCrossentropy)が、 モデルの出力をシグモイド関数に通して確率に変換する処理を内部で行います。 これにより、正しい損失計算が可能になります。 一方、モデルが最終層でシグモイド活性化関数を適用し、確率を直接出力する場合は、 from_logits=Falseを指定する必要があります。この場合、 損失関数はモデルの出力をそのまま使用し、シグモイド関数の適用は行わないため、 正しい損失計算が行われます。 optimizerは学習を勧めるためのアルゴリズムですね。重みを予測結果と真の値との 差を損失関数で定義して、それを最小にするようにします。 今回はadamを指定していますね。このadamがよく選ばれている印象があります。 lossは先にも述べた損失関数ですね。これは分類なのか、今回みたいに2者択一形式 なのか等で適切な損失関数を選ぶ必要があります。 metrics=['accracy']で正答率を確認できます。 model.summary()を見てみましょう。 Total params: 2,259,265 Trainable params: 1,281 Non-trainable params: 2,257,984 このようなパラメーターになっています。 新たにトレーニング可能なパラメーターが増えていますね。
作ったmodelをトレーニングして行こう!!
まずは今の段階での評価を見てみましょう。
#トレーニング前のモデルを検証
loss0, accuracy0 = model.evaluate(validation_dataset)
print("initial loss: {:.2f}". format(loss0))
print("initail accuracy : {:.2f}".format(accuracy0))
上記でvalodation_datasetを使って犬と猫を分類してその結果を確認します。 出力はこんな感じです。 initial loss: 0.83 / initail accuracy : 0.45 まぁ2択の結果で正答率は45%ではさっぱりですね。まぁまだ学習前ですからね。
initial_epochs = 10
#訓練
history = model.fit(
train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset
)
それではecochを10回にしてtrain_datasetを使って訓練してみましょう。 訓練の結果を確認できるように、結果をhistoryでもらっていきます。 10回のトレーニングが終わったら結果を以下のコードで可視化してみましょう。
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(4,4))
#縦2横1のグラフの1個目という意味
plt.subplot(2,1,1)
plt.plot(acc, label='training Accuracy')
plt.plot(val_acc, label='validation Accuracy')
#plt.legend(loc='lower right'):プロットの凡例を表示し、その位置を右下に設定します。
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
#plt.ylim([min(plt.ylim()), 1]):y軸の範囲を設定します。最小値は現在のy軸の最小値とし、最大値は1に設定しています
plt.ylim([min(plt.ylim()), 1])
plt.title('Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
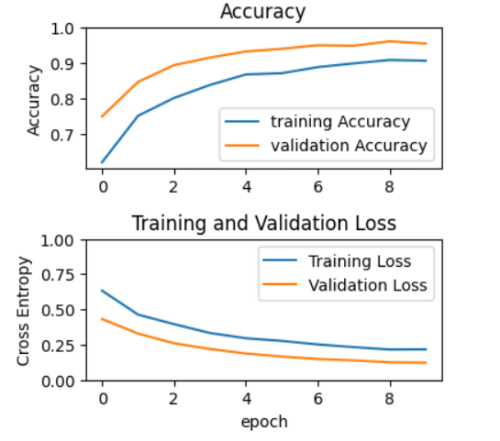
グラフにすると一目瞭然ですね。上が正答率で下がlossですね。 正答率は90-95%位がでますね。すばらしい!
ファインチューニング
さて続いてファインチューニングです。前回の学習では事前学習した部分は凍結しているので 重みの更新は行われません。より今の分類タスクに適合させれるために、事前学習の上位層を 解凍して訓練して学習を行ってみましょう。
#ベースモデルを解凍
base_model.trainable = True
print("number of layers in the base model", len(base_model.layers))
まずはmodelを全て解凍します。 出力は number of layers in the base model 154 となります。modelの層が154層ある とうい事ですね。解凍して使用するのは上位層なのでmodelの1-100までを再度凍結します。
ここで上位層がなんで100以降なんだ?となりますね。 機械学習では上位層は出力層側です。下位は入力層側です。 一般的に下位層は画像のエッジや色などをとらえる非専門的な層ですね。 そして出力層はよりタスクに即した、 専門的な層ということになります。 なので今回は膨大な機械学習をすでに終えている、下位層のパラメータはいじらないで、より専門的な部分の 層の一部を、今回の犬猫分類器用にチューニングしているんですね。
fine_tune_at = 100
#150のうち1-100までを凍結
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
さてもう一度modelをコンパイルしましょう。学習率を低く設定している理由は、 転移学習で既に学習済みの重みが含まれているためです。学習率が高すぎると、 学習済みの重みが急激に変化し、学習済みモデルの有益な特徴が失われる可能性があります。 学習率を低く設定することで、微調整の過程で学習済みの重みがゆっくりと更新され、 有益な特徴を維持しながら新しいタスクに適応することができます。 学習率は、ニューラルネットワークの学習中に重みを更新する際のステップサイズを決定する パラメータです。学習率が大きすぎると、学習が不安定になり、収束しないことがあります。 一方、学習率が小さすぎると、学習が遅くなり、局所最適解に捕まりやすくなります。 適切な学習率を選択することは、ニューラルネットワークの学習において重要な要素です。
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),
metrics=['accuracy'])
ここで毎度のmodel.summary()をして見てみましょう。パラメーターは以下の様になっています。 Total params: 2,259,265 Trainable params: 1,862,721 Non-trainable params: 396,544 訓練できるパラメーターが大分増えたのがわかりますね。それでは再度訓練をしてみましょう。
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)
total_epochsは20だが、実際の学習の回数はfine_tune_epochsの10回、 total_epochsをしているのはプロットで前回10回学習しているので、 今回の学習を11回目から 開始するためです。こうしておかないと後で訓練結果を見るときに分かりにくいですからね。 さて今回もhistory_fineの中を見てみましょう。
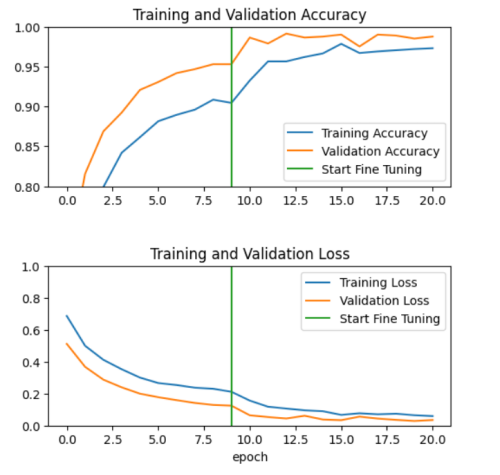
ファインチューニング後もしっかり改善しているのがわかりますね。 それでは、テスト用の画像でevaluateしてみましょう。
loss, accuracy = model.evaluate(test_dataset)
print("test accuracy:", accuracy)
上記の出力結果は test accuracy 1.0 です。テスト用画像は100%分類できました。 それでは実際の分類の結果も可視化してみましょう。
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
predictions = model.predict_on_batch(image_batch).flatten()
predictions = tf.nn.sigmoid(predictions)
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
plt.figure(figsize=(6, 6))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")

Predictions: [0 1 0 0 0 1 1 0 1 1 0 0 0 0 1 0 0 0 0 1 1 0 0 0 0 0 0 1 0 1 1 0] Labels: [0 1 0 0 0 1 1 0 1 1 0 0 0 0 1 0 0 0 0 1 1 0 0 0 0 0 0 1 0 1 1 0] 完璧に分類できていますね!!すばらしい!
訓練したmodelをローカルにセーブしてみよう
さて、ここまでで転移学習をしてみました。ここからはチュートリアルにはありませんが、 modelの保存、ダウンロード、アップロード、自前の画像の分類へと続けて行きましょう。 ここまでやりきると、すこし機械学習した気分が味わえますよね!
model.save("./save/saveModel")
モデルをセーブするのはとても簡単です。上記コードを実行するのみ。 実行前にcolab上にsaveフォルダーを 準備しておきましょう。実行した後はこんな風になります。
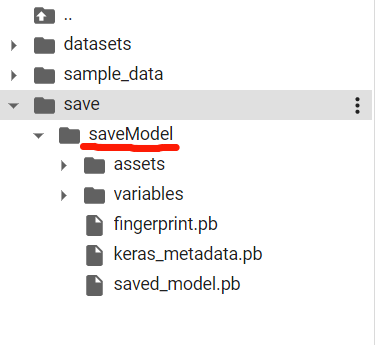
続いてロードしてみましょう。以下のコードでロードできます。
loaded_model = tf.keras.models.load_model("./save/saveModel")
本当にロードできているか確認しましょう。
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
predictions = loaded_model.predict_on_batch(image_batch).flatten()
predictions = tf.nn.sigmoid(predictions)
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")

Predictions: [0 0 1 0 0 1 1 1 1 0 0 0 0 0 1 1 1 1 0 0 1 1 0 1 0 1 1 0 0 0 1 1] Labels: [0 0 1 0 0 1 1 1 1 0 0 0 0 0 1 1 1 1 0 0 1 1 0 1 0 1 1 0 0 0 1 1]
ばっちり機能していますね。しかしこれではcolabの接続が切れたらデータは 消えてしまいますので、続いてmodelをダウンロードしていきましょう。
modelをローカル環境にダウンロード
colabからはzipに圧縮しないとダウンロード出来ないみたいなので、まずはzipにします。 colabにforDownloadという名前でフォルダーを作成します(名前は何でもいいです。)
!zip -r ./forDownload/saveModel.zip ./save/saveModel
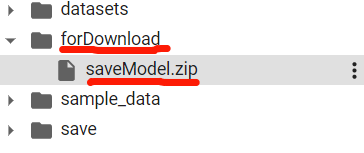
zipファイルができました。それではこれをdwonloadしましょう。
from google.colab import files
files.download('forDownload/saveModel.zip')
これでローカルのダウンロードフォルダーにsaveModel.zipファイルが ダウンロードされます。
ローカル環境からmodelをアップロードしよう
まずはcolabを新しく開きましょう。いままでのcolab環境とは異なる環境でも、 modelを簡単に使用出来ることを確認しましょう。まずは必要なライブラリをインポートします。
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
必要なライブラリもこれだけで動きます。シンプルですね。それではローカルにある modelをuploadしましょう。colabにuploadsというフォルダーを作成して、その フォルダーを右クリックしてアップロードを選択して、先ほどダウンロードした saveModel.zipファイルをuploadしてください。zipのままuploadしないとできないので、 注意してくださいね。

上記のようにcolabにzipファイルがアップロードされたので、これを使用できるように 解凍しましょう。解凍場所のためにcolabにdownModelというフォルダーを作成しましょう。 (フォルダー名にセンスが無くて申し訳ありません、各自でいい感じの名前つけてくださいね。)
!unzip uploads/saveModel.zip -d ./downModel
unzipの後は前半が解凍するファイル、後半が解凍する場所を指定していますね。
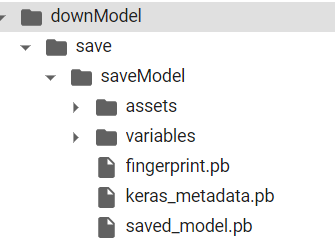
上記のようにdownModelの中に目的のmodelがuploadされました。
アップロードしたモデルを使って自前の画像を分類してみましょう
ではアップロードしたモデルをloadしましょう。
load_model = tf.keras.models.load_model("./downModel/save/saveModel")
load_model.summary()
load_summary()してみると、しっかりとmodelがloadされているのが確認できますね。 それでは、インターネットから適当に拾ってきた猫犬の画像を分類させてみましょう。 ここで筆者は超絶にハマりました。。画像の前処理の事がしっかりわかってないと、 とても大変だとうことをいやって程痛感しました。しかし、無事できたのでやり方を 紹介します。画像の読み方は勉強のために2通り紹介します。 じつは2通りなのは1つ目に紹介する方法でどうやってもうまくいかなかったので2つ目を 試して、それでできたので、1つ目の正しいやり方が分かったので2通りなのですが(笑) まぁプログラミングではtry and errorですよね!
まずははネットから犬と猫の2枚の画像をpicフォルダーにアップロードしましょう。 やり方は簡単です、ローカルフォルダー(自分のパソコンのフォルダー)に画像を 保存して、picフォルダーで右クリックしてアップロードを選択して、保存した画像を 選択してuploadするだけです。
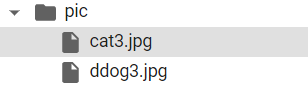
上記のようなファオルダー構成になります。それではいよいよ試してみましょう。
# 画像のパスとサイズ
img_path = './pic/ddog3.jpg' # ここにあなたの画像のパスを指定してください
# 学習の時に指定した画像のサイズをそのまま指定
img_size = (160, 160, 3)
# 画像の読み込みとリサイズ
img = Image.open(img_path)
img = img.resize(img_size[:2])
#リサイズした後の画像を表示
plt.imshow(img)
# numpy配列に変換
img_array = np.array(img)
print("変換前: ",img_array.shape)
# 入力画像はバッチ入力されているので、バッチ次元が必要
img_array = np.expand_dims(img_array, axis=0)
print("バッチ次元を追加後: ",img_array.shape)
# モデルによる予測
predictions = load_model.predict(img_array)
# ロジットをシグモイド関数に通す
predictions = tf.nn.sigmoid(predictions)
# modelの予想結果を表示0に近いほど猫、1に近いほど犬と予想している
print(predictions)
# 確率が0.5以上なら1(犬)、それ未満なら0(猫)を出力
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:', predictions.numpy())
変換前: (160, 160, 3) バッチ次元を追加後: (1, 160, 160, 3) 1/1 [==============================] - 0s 43ms/step tf.Tensor([[0.9973345]], shape=(1, 1), dtype=float32) Predictions: [[1]]
予想の結果は0.9973345と、かなり1に近い数字を出しており犬と 予想していることがわかりますね。ばっちり出来ました。 簡単やん!!と思うかもしれませんが、実はめちゃくちゃ苦戦しました。 僕はまったくプログラミング教育は受けたことがないので、まぁ初心者ですので、 独自の画像を入力する方法なんかわからないので、chat GPT君と相談しながら進めましたが、 画像入力の時にまずつまずいたのが、上記のコード内にもコメントに書いていますが、 入力画像がバッチで要求されている所ですね。画像のみなら(160,160,3)の形式で いいのですが、機械学習はバッチごとに行われるので、もう一次元追加しなくては いけないのですね。なので上記の通り、バッチの次元を追加する必要がありました。 そして、それが出来たら入力のエラーは出なくなったんですが、予想がどんな画像を いれても猫、つまり0近辺しか示さなくなりました。 これはかなり苦労しましたが、結果的には画像はそのままいれれば良かったということでした。 正規化したり、preprocess_input(x)でMobileNetV2の入力用に(-1から1)にする 処理を入力時に行っていたのが問題でしたね。その処理は不要でした。これが次の tf.keras.utils.image_dataset_from_directoryを使う方法でわかりました。 いやー前処理はマジで鬼門だ!!素人にはプログラミングは難しいですね。。 画像のパスを変更して準備した猫の画像でもためしてみてください。うまくいくと思います!
さて続いてtf.keras.utils.image_dataset_from_directoryを使用してやって見ましょう。 これを使用するにはフォルダーの構成が重要です。指定したフォルダーの中に1つフォルダーを 作成して、その中に試したい画像をいれてください。tf.keras.utils.image_dataset_from_directory は、本来はフォルダーの中の画像をフォルダー名をcalss_nameとして分類して画像を 扱い安くしてくれるものでしたからね。今回は犬や猫とファルダー分類しないでtestフォルダーの中に 入れておきます。なのでclass_nameは1つだけです。
上記のようなフォルダ構成にしましょう。
import shutil
checkpoints_dir = './pic/.ipynb_checkpoints'
try:
# ディレクトリが存在する場合、削除する
shutil.rmtree(checkpoints_dir)
except FileNotFoundError:
# ディレクトリが存在しない場合、何もしない
pass
上記はcolabでファイルの変更等をすると、隠しフォルダーが一個できて、それをclassを 認識してしまうので、邪魔なので消しておくためのコードです。
check_batch = 5
image_size = (160,160)
check_dir = "./pic"
check_dataset = tf.keras.utils.image_dataset_from_directory(
check_dir,shuffle=False,batch_size=check_batch,image_size=image_size
)
上記のcheck_batchはフォルダーの中の写真の枚数を指定してください。
check_class_names = check_dataset.class_names
print(check_class_names)
上記でtestと出力されますね。フォルダー名がちゃんとclass_nameになっていますね。
image_batch, label_batch = check_dataset.as_numpy_iterator().next()
predictions = load_model.predict_on_batch(image_batch).flatten()
predictions = tf.nn.sigmoid(predictions)
predictions2 = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('answer:\n', predictions2)
plt.figure(figsize=(6, 6))
for i in range(check_batch):
ax = plt.subplot(check_batch, 2, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.axis("off")

Predictions:
[0.00373647 0.9999424 0.9997851 0.9976732 0.04834275]
answer:
tf.Tensor([0 1 1 1 0], shape=(5,), dtype=int32)
画像は猫、犬、犬、犬、猫で予想の答えも0,1,1,1,0としっかり予想出来ています。 完璧ですね。
さて、長くなりましたが、これで転移学習チュートリアルは終了です。 これで転移学習後のmodleをローカルに保存して、後日そのmodelをuploadして 自前の分類をなんてことまでできるようになっていると思います。 いやー、なかなか難しかったですね。unityとかならエラーが映像になって確認 できますが、これは数字のみ、しかもそのエラーを出力するのも一苦労ですねよね。 自分でgoogleのチュートリアルをやって、かなり詰まった部分もあったので自分の 勉強も含めてまとめました! ここまで読んでいただいて本当にありがとうございました。誰かのお役に立てれば 幸いです。